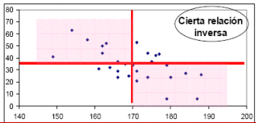
INFERENCIA ESTADÍSTICA
Al conjunto de procedimientos
estadísticos que permiten pasar de lo particular, la muestra, a lo general, la
población, le denominamos inferencia estadística
Dos formas de inferencia
estadística:
- ESTIMACIÓN del valor en la población (Parámetro)
a partir de un valor de la muestra (Estimador)
- CONTRASTE DE HIPÓTESIS, a partir de valores de
la muestra, se concluye si hay diferencias entre ellos en la población
· Las dos formas de inferencia estadística
- Estimaciones puntuales o a través de intervalos
de confianza para aproximarnos a valor de un parámetro
- Pruebas de hipótesis ¿el valor obtenido es
diferente del valor especificado por H0?
ESTIMACIONES
Proceso de utilizar información de
una muestra para extraer conclusiones acerca de toda la población.
Se utiliza la información
recogida para estimar un valor.
Puede realizarse ESTIMACIÓN
PUNTUAL o ESTIMACIÓN POR INTERVALOS mediante el cálculo de INTERVALOS DE
CONFIANZA.
ESTIMACIÓN PUNTUAL
Consiste en considerar al valor
del estadístico muestral como una estimación del parámetro poblacional.
Por ejemplo, si la TAS media de
una muestra es 125 mmHg, una estimación puntual es considerar este valor como
una aproximación a la TAS media poblacional.
ESTIMACIÓN POR INTERVALOS
Consiste en calcular dos valores
entre los cuales se encuentra el parámetro poblacional que queremos estimar con
una probabilidad determinada, habitualmente el 95%
Por ejemplo, a partir de los
datos de una muestra hemos calculado que hay un 95% de probabilidad de la TAS
media de una población esté comprendida entre 120 y 130 mmHg (120 y 130 son los
límites del intervalo de confianza)
Se pueden crear para cualquier
parámetro de la población
Se utilizan como indicadores de
la variabilidad de las estimaciones
Cuanto más “estrecho” sea, mejor
EJEMPLO INFERENCIA Y ESTIMACIÓN
·
- Estudio tiempos de curación de úlceras en
muestra de 100 pacientes.
- Media del tiempo muestra 1 = 53,77 días
- Media tiempo muestra 2 = 57,08 días
- Si seleccionáramos muchas muestras, cada una nos
daría un valor distinto.
- Construimos histograma con los estimadores de la
media de tratamiento calculados en 200 muestras distintas de 100 pacientes cada
una
ERROR ESTÁNDAR
Es la medida que trata de captar
la variabilidad de los valores del estimador (en este caso la media de los días
de curación de la úlcera)
El error estándar de cualquier
estimador mide el grado de variabilidad en los valores del estimador en las
distintas muestras de un determinado tamaño que pudiésemos tomar de una
población.
Cuanto más pequeño es el error
estándar de un estimador, más nos podemos fiar del valor de una muestra
concreta.
Si en lugar de variar el valor de
la media en las muestras entre 52 y 64 días, variara entre 20 y 90 días, sería
menos probable que al seleccionar una muestra y calcular su media, ésta
estuviera cercana a 57,46, que es el valor de la media en la población
CÁLCULO DEL ERROR ESTÁNDAR
Depende de cada estimador:
- Error estándar para una media: s/√¯n
- Error estándar para una proporción: √¯p(1-p)/n
De ambas fórmulas se deduce que,
mientras mayor sea el tamaño de una muestra, menor será el error estándar.
TEOREMA CENTRAL DEL LÍMITE:
Para estimadores que pueden ser
expresados como suma de valores muestrales, la distribución de sus valores
sigue una distribución normal con media de la de la población y desviación
típica igual al error estándar del estimador de que se trate.
Si sigue una distribución normal,
sigue los principios básicos de ésta:
- ± 1S 68,26% de las observaciones
- ± 2S 95,45% de las observaciones
- ± 1,95S 95% de las observaciones
- ± 3S 99,73% de las observaciones
- ± 2,58S 99% de las observaciones
INTERVALOS DE CONFIANZA
Son un medio de conocer el
parámetro en una población midiendo el error que tiene que ver con el azar
(error aleatorio)
Se trata de un par de números
tales que, con un nivel de confianza determinados, podamos asegurar que el
valor del parámetro es mayor o menor que ambos números.
Se calcula considerando que el
estimador muestral sigue una distribución normal, como establece la teoría
central del límite.
Cálculo:
- I.C. de un parámetro= estimador ± z(e.estándar)
- Z es un valor que depende del nivel de confianza
1-a con que se quiera dar el intervalo
- Para nivel de confianza 95% z=1,96
- Para nivel de confianza 99% z=2,58
- El signo ± significa que cuando se elija el
signo negativo se conseguirá el extremo inferior del intervalo y cuando se
elija el positivo se tendrá el extremo superior
Mientras mayor sea la confianza
que queramos otorgar al intervalo, éste será más amplio, es decir el extremo
inferior y el superior del intervalo estarás más distanciados y, por tanto, el
intervalo será menos preciso.
Se puede calcular intervalos de
confianzas para cualquier parámetro: medias aritméticas, proporciones, riesgos
relativos, odds ratio, etc.
CONTRASTES DE HIPÓTESIS
Para controlar los errores
aleatorios, además del cálculo de intervalos de confianza, contamos con una
segunda herramienta en el proceso de inferencia estadística: los tests o
contrastes de hipótesis
Con los intervalos nos hacemos
una idea de un parámetro de una población dando un par de números entre los que
confiamos que esté el valor desconocido
Con los contrastes (tests) de
hipótesis la estrategia es la siguiente:
- Establecemos a priori una hipótesis acerca del
valor del parámetro
- Realizamos la recogida de datos
- Analizamos la coherencia de entre la hipótesis
previa y los datos obtenidos
Son herramientas estadísticas
para responder a preguntas de investigación: permite cuantificar la
compatibilidad entre una hipótesis previamente establecida y los resultados
obtenidos
Sean cuales sean los deseos de
los investigadores, el test de hipótesis siempre va a contrastar la hipótesis
nula (la que establece igualdad entre los grupos a comparar, o lo que es lo
mismo, la no que no establece relación entre las variables de estudio)
ERRORES DE HIPÓTESIS
- Con una misma muestra podemos aceptar o rechazar
la hipótesis nula, todo depende de un error, al que llamamos α
- El error α es la probabilidad de equivocarnos al
rechazar la hipótesis nula
- El error α más pequeño al que podemos rechazar
H0 es el error p
- Habitualmente rechazamos H0 para un nivel α
máximo del 5% (p<0,05)
- Es lo que llamamos “significación estadística”