ESTUDIO CONJUNTO DE DOS VARIABLES
Una de las formas de recoger los datos obtenidos observando dos variables en varios individuos de una muestra, es en una tabla.
- En las filas tendremos los datos de un individuo.
- En cada columna se representará los valores que toma una variable sobre los mismos.
- Los individuos no se muestran en ningún orden particular.
Nuestro objetivo será intentar reconocer a partir del mismo si hay relación entre las variables, de qué tipo, y si es posible predecir el valor de una de ellas en función de la otra.
DIAGRAMAS DE DISPERSIÓN O NUBE DE PUNTOS

RELACIÓN ENTRE VARIABLES

PREDICCIÓN DE UNA VARIABLE EN FUNCIÓN DE OTRA

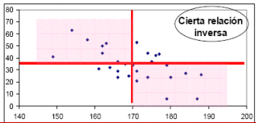
RELACIÓN DIRECTA E INVERSA
Incorrelación: Para valores de X por encima de la media tenemos de Y por encima y por debajo en proporciones similares.

Relación directa: para los valores X mayores que la media le corresponden valores de Y mayores también, y viceversa con ambos.

Relación inversa: para los valores de X mayores que la media le corresponden valores de Y menores.
MODELOS DE ANÁLISIS DE REGRESIÓN

REGRESIÓN LINEAL SIMPLE: CORRELACIÓN Y DETERMINACIÓN
- Se trata de estudiar la asociación lineal entre dos variables cuantitativas
- Ejemplo: influencia de la edad en las cifras de Tensión arterial Sistólica
- Regresión lineal simple: una sola variable independiente
- Regresión lineal múltiple: más de una variable independiente
- Ecuación de la recta: y = ax + b (ej: TAS=a· edad +b)
- Pendiente de la recta a = β1
- Punto de intersección con el eje de coordenadas b=β0
- Pendiente de la recta a = β1
- Punto de intersección con el eje de coordenadas b=β0
- Β1 expresa la cantidad de cambio que se produce en la variable dependiente por unidad de cambio de la variable independiente
- Β0 expresa cuál es el valor de la variable dependiente cuando la independiente vale cero
- Modelos lineales deterministas: la variable independiente determine el valor de la variable dependiente. Entonces para cada valor de la variable independiente sólo habría un valor de la dependiente
- Modelos lineales probabilísticos: Para cada valor de la variable independiente existe una distribución de probabilidad de valores de la dependiente, con una probabilidad entre 0 y 1.
- La recta a determinar es aquélla con la menor distancia de cada punto a ella.

ANÁLISIS DE CORRELACIÓN
El análisis de correlación se utiliza con el propósito de disponer de un indicador cuantitativo que permite sintetizar el grado de la asociación entre variables.
VARIABLES CUANTITATIVAS NORMALES:
Coeficiente de Correlación r de Pearson: mide el grado de la relación de dependencia que existe entre las variables (x,y), cuyos valores van desde -1, correspondiente a una correlación negativa perfecta, hasta 1, correspondiente a una correlación positiva perfecta.
La magnitud del Coeficiente de Correlación (r) indica cuán cerca están los puntos de la recta, tomando valores entre 1 y -1.
VARIABLES ORDINALES:
El coeficiente de Correlación por Rango de rho de Spearman es una medida de asociación que requiere que ambas variables en estudio sean medidas por lo menos en una escala ordinal.
ALGUNAS DE LAS FORMAS DE COMPROBAR LA NORMALIDAD DE LOS DATOS
- Prueba de Kolmogorov-Smirvov
- Prueba de Shapiro-Wilk
- Y = β1 · x + β0
- Yi= β1 · x + β0 + ei
- Y sería la media de la variable dependiente en un grupo con el mismo valor de la variable independiente Yi= y + ei
- Para construir un modelo de regresión lineal hace falta conocer: Punto de intersección con el eje de coordenadas=β0 y la Pendiente de la recta a = β1
- No hay un modelo determinista: hay una nube de puntos y buscamos la recta que mejor explica el comportamiento de la variable dependiente en función de la variable independiente

Teniendo una
nube de puntos, ¿cómo elegir la recta que mejor se ajuste a esos puntos?:
Mediante el método de los mínimos cuadrados.
Se trata de la
recta que hace mínimo el cuadrado de la suma de las distancias verticales desde
ella hasta cada uno de los puntos de la nube.
· Coeficiente de correlación (Pearson y Spearman):
Número adimensional (entre -1 y 1) que mide la fuerza y el sentido de la
relación lineal entre dos variables.
·
r= β1 • sx /sy
· Coeficiente de determinación: número
adimensional (entre 0 y 1) que dá idea de la relación entre las variables
relacionadas linealmente. Es r2